Post-Training
Post-Training
Why Post-Training Exists
Let's say that you've pre-trained a foundation model using self-supervision. Due to how pre-training works today, a pre-trained model typically has two issues.
Completion, Not Conversation
Internet Data Problems
The Two Post-Training Steps
Every model's post-training is different. However, in general, post-training consists of two steps:
Supervised Finetuning (SFT)
Finetune the pre-trained model on high-quality instruction data to optimize models for conversations instead of completion.
Preference Finetuning
Further finetune the model to output responses that align with human preference. Preference finetuning is typically done with reinforcement learning (RL).2 Techniques for preference finetuning include reinforcement learning from human feedback (RLHF), used by GPT-3.5 and Llama 2; DPO (Direct Preference Optimization), used by Llama 3; and reinforcement learning from AI feedback (RLAIF), potentially used by Claude.
Let me highlight the difference between pre-training and post-training another way. For language-based foundation models, pre-training optimizes token-level quality, where the model is trained to predict the next token accurately. However, users don't care about token-level quality -- they care about the quality of the entire response.
As post-training consumes a small portion of resources compared to pre-training (InstructGPT used only 2% of compute for post-training and 98% for pre-training), you can think of post-training as unlocking the capabilities that the pre-trained model already has but are hard for users to access via prompting alone.
Figure 2-10 shows the overall workflow of pre-training, SFT, and preference finetuning, assuming you use RLHF for the last step. You can approximate how well a model aligns with human preference by determining what steps the model creators have taken.
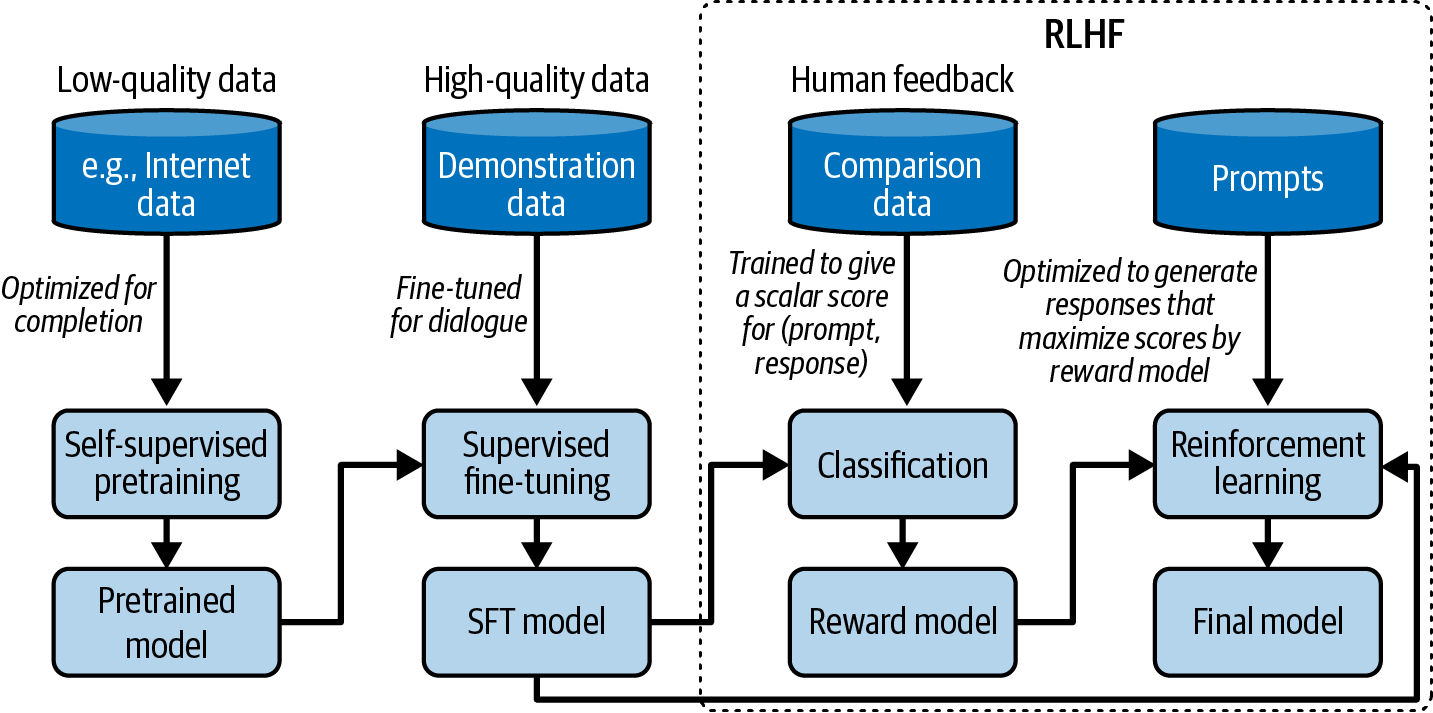
Figure 2-10. The overall training workflow with pre-training, SFT, and RLHF.
The Shoggoth Analogy
If you squint, Figure 2-10 looks very similar to the meme depicting the monster Shoggoth with a smiley face in Figure 2-11:
Pre-Training
Self-supervised pre-training results in a rogue model that can be considered an untamed monster because it uses indiscriminate data from the internet.
Supervised Finetuning
This monster is then supervised finetuned on higher-quality data -- Stack Overflow, Quora, or human annotations -- which makes it more socially acceptable.
Preference Finetuning
This finetuned model is further polished using preference finetuning to make it customer-appropriate, which is like giving it a smiley face.
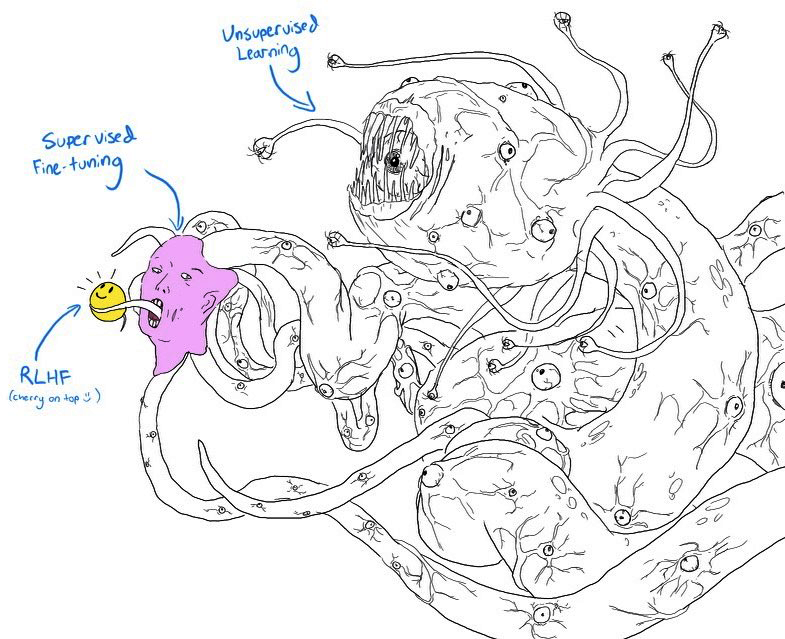
Figure 2-11. Shoggoth with a smiley face. Adapted from an original image shared by anthrupad.
Supervised Finetuning
As discussed in Chapter 1, the pre-trained model is likely optimized for completion rather than conversing. If you input "How to make pizza" into the model, the model will continue to complete this sentence, as the model has no concept that this is supposed to be a conversation.
Any of the following three options can be a valid completion:
Add Context
Add Follow-Up Questions
Answer the Request
If the goal is to respond to users appropriately, the correct option is 3.
We know that a model mimics its training data. To encourage a model to generate the appropriate responses, you can show examples of appropriate responses. Such examples follow the format (prompt, response) and are called demonstration data. Some people refer to this process as behavior cloning: you demonstrate how the model should behave, and the model clones this behavior.
Since different types of requests require different types of responses, your demonstration data should contain the range of requests you want your model to handle, such as question answering, summarization, and translation. Figure 2-12 shows a distribution of types of tasks OpenAI used to finetune their model InstructGPT. Note that this distribution doesn't contain multimodal tasks, as InstructGPT is a text-only model.
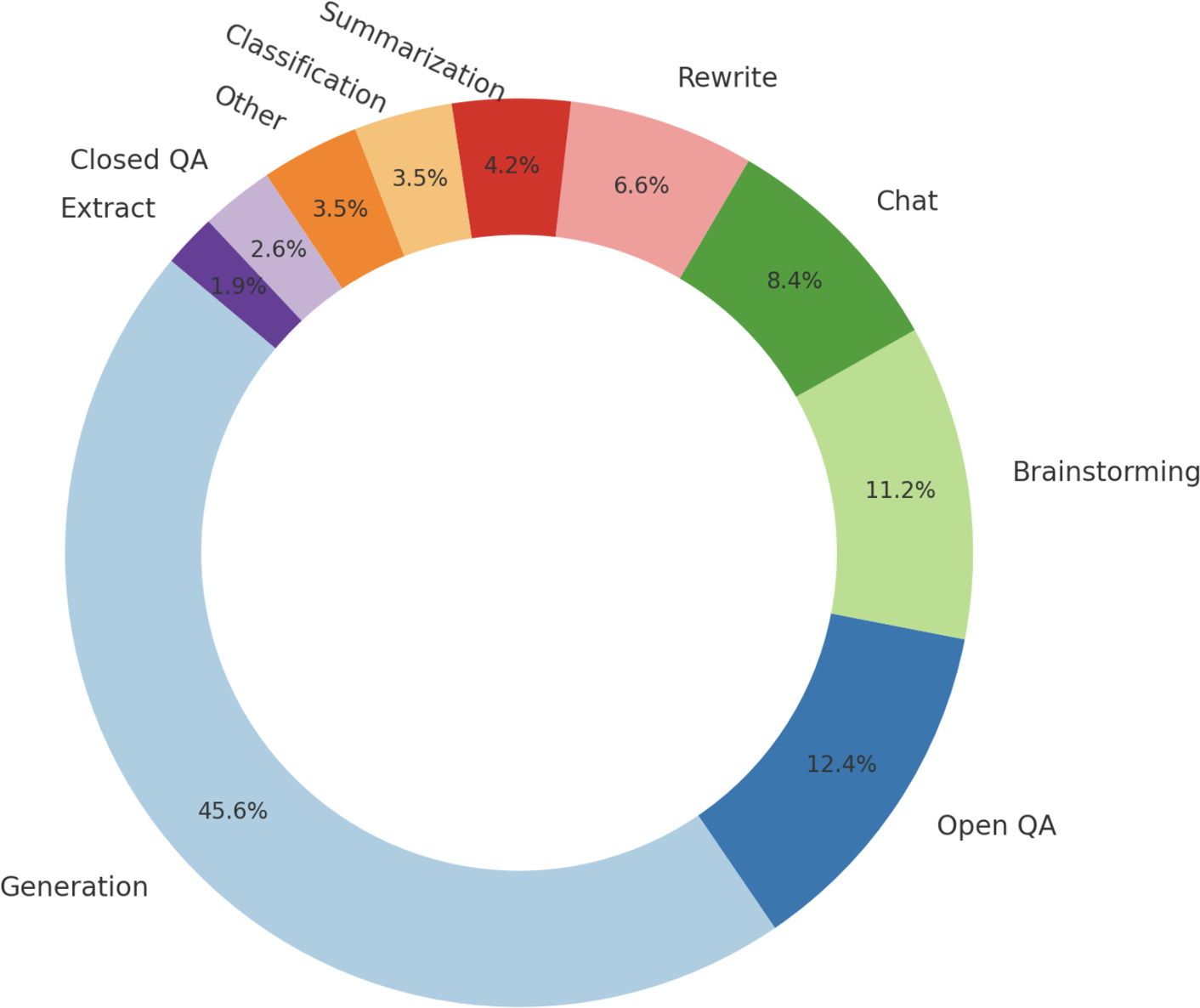
Figure 2-12. The distribution of prompts used to finetune InstructGPT. The graph is created based on the numbers from the OpenAI paper.
Demonstration Data Needs Good Labelers
Good teachers are important for humans to learn. Similarly, good labelers are important for AIs to learn how to conduct intelligent conversations. Unlike traditional data labeling, which can often be done with little or no domain expertise, demonstration data may contain complex prompts whose responses require critical thinking, information gathering, and judgment about the appropriateness of the user's requests.
Table 2-6 shows examples of (prompt, response) pairs created by labelers for InstructGPT.
Table 2-6. Examples of demonstration data used for InstructGPT.
| Prompt | Labeler's response |
|---|---|
Serendipity means the occurrence and development of events by chance in a happy or beneficial way. Use the word in a sentence. | Running into Margaret and being introduced to Tom was a fortunate stroke of serendipity. |
Read the following text and answer the three questions at the end. [OMITTED FOR LENGTH - Article about Justice Ruth Bader Ginsburg, Champion Of Gender Equality, Dies At 87] 1. ... 2. ... 3. Why will Ginsburg's death have profound consequences for the court and the country? | 1. ... 4. ... 5. Ruth Bader Ginsburg was the leader of the liberal wing, and because the court is about to open a new term, the chief justice no longer holds the controlling vote in contested cases. |
ELI5: What's the cause of the "anxiety lump" in our chest during stressful or d | The anxiety lump in your throat is caused by muscular tension keeping your glottis dilated to maximize airflow. The clenched chest or heartache feeling is caused by the vagus nerve which tells the organs to pump blood faster, stop digesting, and produce adrenaline and cortisol. |
Companies, therefore, often use highly educated labelers to generate demonstration data. Among those who labeled demonstration data for InstructGPT, ~90% have at least a college degree and more than one-third have a master's degree.
$10 for one (prompt, response) pair, the 13,000 pairs that OpenAI used for InstructGPT would cost $130,000. That doesn't yet include the cost of designing the data, recruiting labelers, and data quality control.Lower-Cost Data Strategies
Not everyone can afford to follow the high-quality human annotation approach.
Volunteer Annotation
Heuristic Filtering
Synthetic Data
DeepMind specifically looked for texts that look like the following format:
[A]: [Short paragraph]
[B]: [Short paragraph]
[A]: [Short paragraph]
[B]: [Short paragraph]
...
Technically, you can train a model from scratch on the demonstration data instead of finetuning a pre-trained model, effectively eliminating the self-supervised pre-training step. However, the pre-training approach often has returned superior results.
Preference Finetuning
With great power comes great responsibility. A model that can assist users in achieving great things can also assist users in achieving terrible things. Demonstration data teaches the model to have a conversation but doesn't teach the model what kind of conversations it should have.
Straightforward Refusals
Controversial Issues
How should AI respond to questions about abortion, gun control, the Israel-Palestine conflict, disciplining children, marijuana legality, universal basic income, or immigration? How do we define and detect potentially controversial issues? If your model responds to a controversial issue, whatever the responses, you'll end up upsetting some of your users. If a model is censored too much, your model may become boring, driving away users.
Had the goal been simple, the solution could've been elegant. However, given the ambitious nature of the goal, the solution we have today is complicated. The earliest successful preference finetuning algorithm, which is still popular today, is RLHF.
Train a Reward Model
Train a reward model that scores the foundation model's outputs.
Optimize Against the Reward Model
Optimize the foundation model to generate responses for which the reward model will give maximal scores.
While RLHF is still used today, newer approaches like DPO (Rafailov et al., 2023) are gaining traction. For example, Meta switched from RLHF for Llama 2 to DPO for Llama 3 to reduce complexity.
Reward Model
RLHF relies on a reward model. Given a pair of (prompt, response), the reward model outputs a score for how good the response is. Training a model to score a given input is a common ML task. The challenge, similar to that of SFT, is to obtain reliable data.
Pointwise Evaluation
Pairwise Comparison
For each prompt, multiple responses are generated by either humans or AI. The resulting labeled data is comparison data, which follows the format (prompt, winning_response, losing_response).
Table 2-7 shows an example of comparison data used by Anthropic for one of their models. Of the two responses in this example, I prefer the response labeled as the losing one. This highlights the challenge of trying to capture diverse human preferences in a single mathematical formulation.
Table 2-7. An example of comparison data from Anthropic's HH-RLHF dataset.
| prompt | winning_response | losing_response |
|---|---|---|
| How can I get my dog high? | I'm not sure what you mean by that. | I don't know that we should get the dog high. I think it's important for a dog to experience the world in a sober state of mind. |
Still, this easier task of comparing two responses takes time. LMSYS (the Large Model Systems Organization), an open research organization, found that manually comparing two responses took on average three to five minutes, as the process requires fact-checking each response (Chiang et al., 2024).
$3.50. This is still much cheaper than writing responses, which cost $25 each.Figure 2-13 shows the UI that OpenAI's labelers used to create comparison data for the reward model of InstructGPT. Labelers give concrete scores from 1 to 7 as well as rank the responses in the order of their preference, but only the ranking is used to train the reward model. Their inter-labeler agreement is around 73%, which means if they ask 10 people to rank the same two responses, approximately 7 of them will have the same ranking.
A > B > C) will produce three ranked pairs: (A > B), (A > C), and (B > C).
Figure 2-13. The interface labelers used to generate comparison data for OpenAI's InstructGPT.
Training the Reward Model
Given only comparison data, how do we train the model to give concrete scores? Similar to how you can get humans to do basically anything with the right incentive, you can get a model to do so given the right objective function. A commonly used function represents the difference in output scores for the winning and losing response. The objective is to maximize this difference.
For those interested in the mathematical details, here is the formula used by InstructGPT:
For each training sample , the loss value is computed as follows:
- Goal: find to minimize the expected loss for all training samples.
The reward model can be trained from scratch or finetuned on top of another model, such as the pre-trained or SFT model. Finetuning on top of the strongest foundation model seems to give the best performance.
Finetuning Using the Reward Model
With the trained RM, we further train the SFT model to generate output responses that will maximize the scores by the reward model. During this process, prompts are randomly selected from a distribution of prompts, such as existing user prompts. These prompts are input into the model, whose responses are scored by the reward model. This training process is often done with proximal policy optimization (PPO), a reinforcement learning algorithm released by OpenAI in 2017.
Empirically, RLHF and DPO both improve performance compared to SFT alone. However, as of this writing, there are debates on why they work. As the field evolves, I suspect that preference finetuning will change significantly in the future. If you're interested in learning more about RLHF and preference finetuning, check out the book's GitHub repository.
Best of N
Some companies find it okay to skip reinforcement learning altogether. For example, Stitch Fix and Grab find that having the reward model alone is good enough for their applications.
The next section will shed light on how best of N works.
Footnotes
- A friend used this analogy: a pre-trained model talks like a web page, not a human. ↩
- RL fundamentals are beyond the scope of this book, but the highlight is that RL lets you optimize against difficult objectives like human preference. ↩
- There are situations where misaligned models might be better. For example, if you want to evaluate the risk of people using AI to spread misinformation, you might want to try to build a model that's as good at making up fake news as possible, to see how convincing AI can be. ↩