Sampling
Sampling
What Sampling Controls
This section discusses different sampling strategies and sampling variables, including temperature, top-k, and top-p. It'll then explore how to sample multiple outputs to improve a model's performance. We'll also see how the sampling process can be modified to get models to generate responses that follow certain formats and constraints.
This section ends with a deep dive into what this probabilistic nature means and how to work with it.
Sampling Fundamentals
Given an input, a neural network produces an output by first computing the probabilities of possible outcomes.
Classification Model
Decision Threshold
Language Model
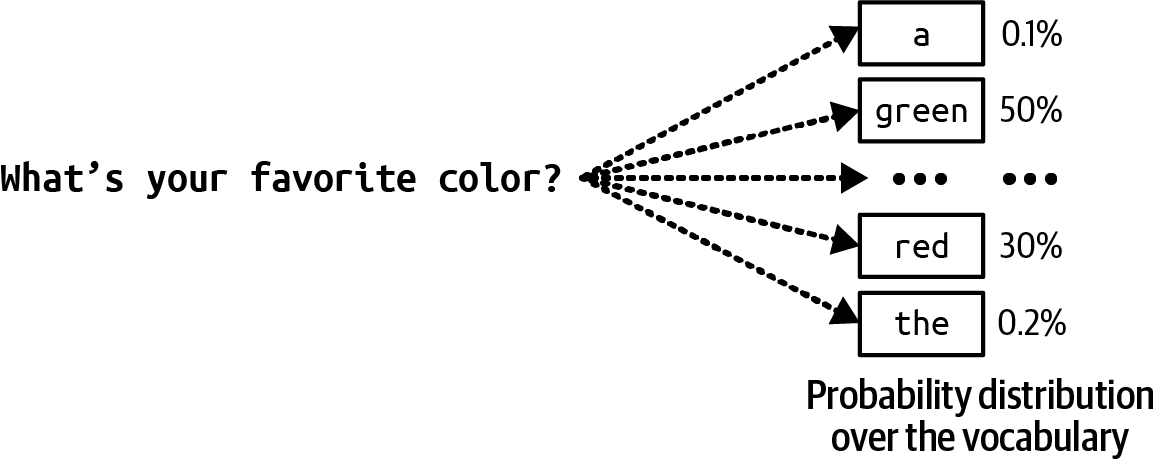
Figure 2-14. To generate the next token, the language model first computes the probability distribution over all tokens in the vocabulary.
Greedy Sampling Versus Distribution Sampling
When working with possible outcomes of different probabilities, a common strategy is to pick the outcome with the highest probability. Always picking the most likely outcome is called greedy sampling.
Works for Classification
Boring for Language
Instead of always picking the next most likely token, the model can sample the next token according to the probability distribution over all possible values. Given the context of "My favorite color is ..." as shown in Figure 2-14, if "red" has a 30% chance of being the next token and "green" has a 50% chance, "red" will be picked 30% of the time, and "green" 50% of the time.
Logits, Probabilities, and Softmax
How does a model compute these probabilities? Given an input, a neural network outputs a logit vector. Each logit corresponds to one possible value. In the case of a language model, each logit corresponds to one token in the model's vocabulary. The logit vector size is the size of the vocabulary.
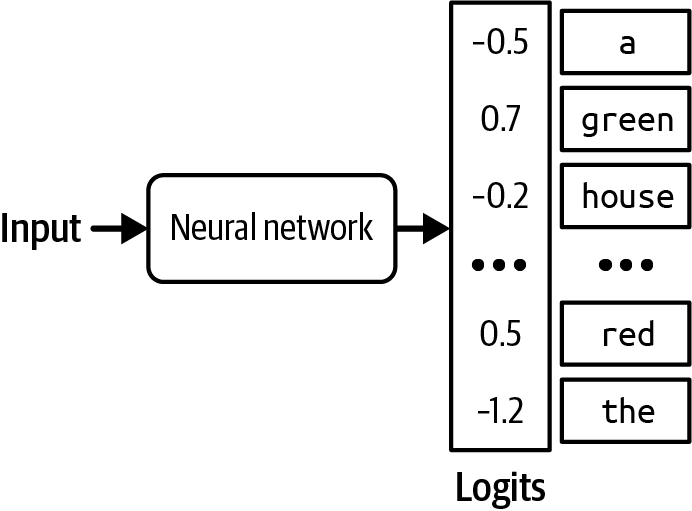
Figure 2-15. For each input, a language model produces a logit vector. Each logit corresponds to a token in the vocabulary.
While larger logits correspond to higher probabilities, logits don't represent probabilities. Logits don't sum up to one. Logits can even be negative, while probabilities have to be non-negative.
Let's say the model has a vocabulary of N and the logit vector is . The probability for the token, , is computed as follows:
Sampling Strategies
The right sampling strategy can make a model generate responses more suitable for your application. One sampling strategy can make the model generate more creative responses, whereas another strategy can make its generations more predictable.
Temperature
One problem with sampling the next token according to the probability distribution is that the model can be less creative. In the previous example, common colors like "red", "green", "purple", and so on have the highest probabilities. The language model's answer ends up sounding like that of a five-year-old: "My favorite color is green". Because "the" has a low probability, the model has a low chance of generating a creative sentence such as "My favorite color is the color of a still lake on a spring morning".
Temperature is a constant used to adjust the logits before the softmax transformation. Logits are divided by temperature. For a given temperature , the adjusted logit for the token is . Softmax is then applied on this adjusted logit instead of on .
Temperature Example
Imagine that we have a model that has only two possible outputs: A and B. The logits computed from the last layer are . The logit for is and is .
Temperature 1
Temperature 0.5
Figure 2-16 shows the softmax probabilities for tokens A and B at different temperatures. As the temperature gets closer to 0, the probability that the model picks token B becomes closer to 1. In our example, for a temperature below 0.1, the model almost always outputs B. As the temperature increases, the probability that token A is picked increases while the probability that token B is picked decreases.
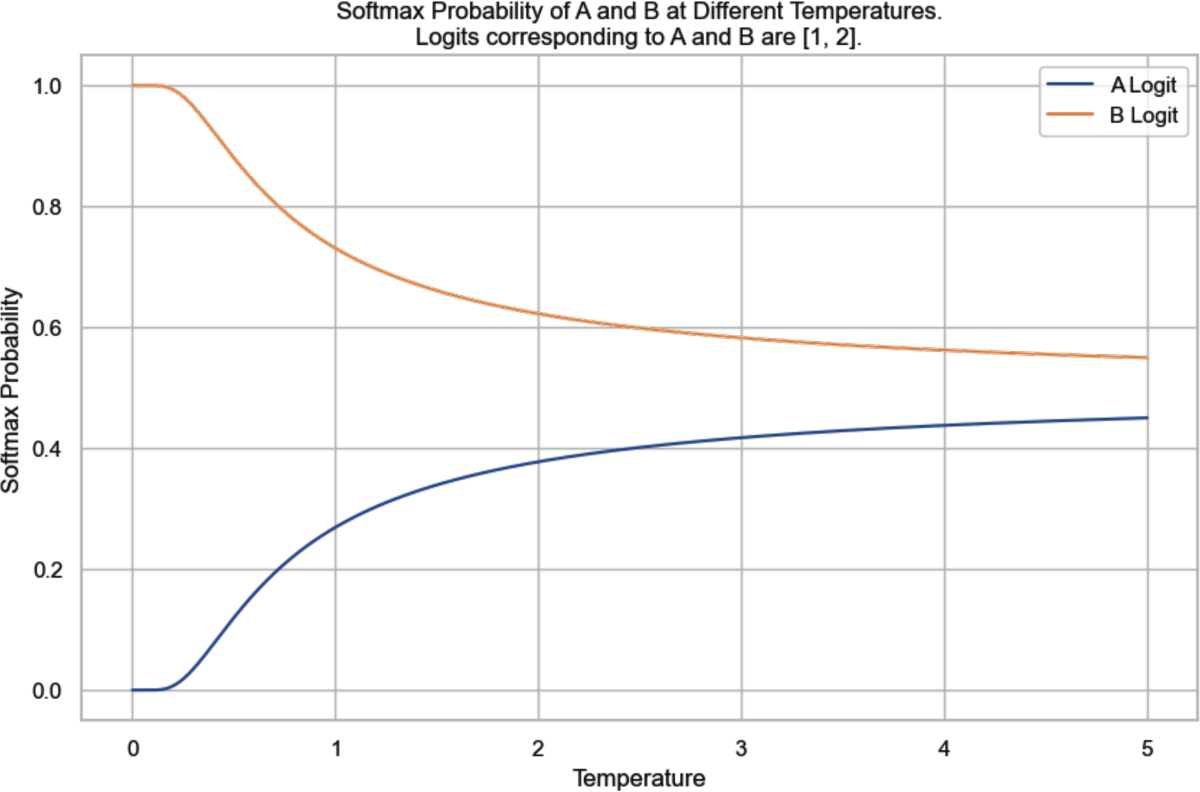
Figure 2-16. The softmax probabilities for tokens A and B at different temperatures, given their logits being 1, 2. Without setting the temperature value, which is equivalent to using the temperature of 1, the softmax probability of B would be 73%.
Model providers typically limit the temperature to be between 0 and 2. If you own your model, you can use any non-negative temperature. A temperature of 0.7 is often recommended for creative use cases, as it balances creativity and predictability, but you should experiment and find the temperature that works best for you.
Logprobs
Many model providers return probabilities generated by their models as logprobs. Logprobs, short for log probabilities, are probabilities in the log scale.
Figure 2-17 shows the workflow of how logits, probabilities, and logprobs are computed.
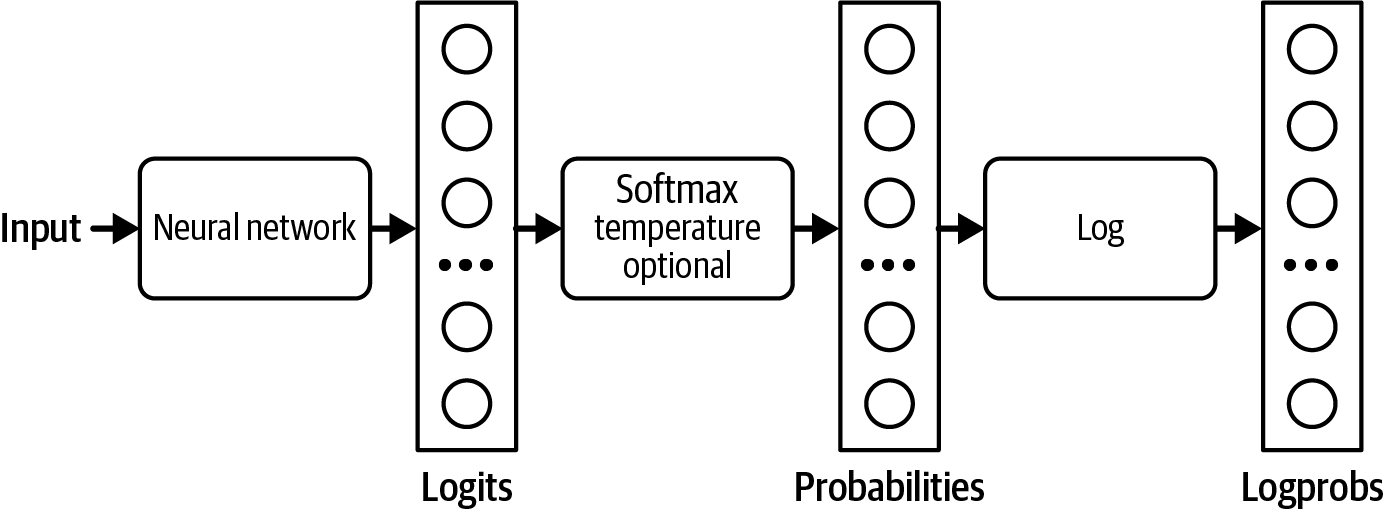
Figure 2-17. How logits, probabilities, and logprobs are computed.
As you'll see throughout the book, logprobs are useful for building applications, especially for classification, evaluating applications, and understanding how models work under the hood.
Top-k
Top-k is a sampling strategy to reduce the computation workload without sacrificing too much of the model's response diversity. Recall that a softmax layer is used to compute the probability distribution over all possible values. Softmax requires two passes over all possible values: one to perform the exponential sum , and one to perform for each value. For a language model with a large vocabulary, this process is computationally expensive.
Compute Logits
After the model has computed the logits, pick the top-k logits.
Apply Softmax Only to Top-k
Perform softmax over these top-k logits only.
Sample From Top Values
The model then samples from these top values. Depending on how diverse you want your application to be, k can be anywhere from 50 to 500 -- much smaller than a model's vocabulary size.
A smaller k value makes the text more predictable but less interesting, as the model is limited to a smaller set of likely words.
Top-p
In top-k sampling, the number of values considered is fixed to k. However, this number should change depending on the situation.
Narrow Prompt
Open-Ended Prompt
Top-p, also known as nucleus sampling, allows for a more dynamic selection of values to be sampled from. In top-p sampling, the model sums the probabilities of the most likely next values in descending order and stops when the sum reaches p. Only the values within this cumulative probability are considered.
Let's say the probabilities of all tokens are as shown in Figure 2-18. If top-p is 90%, only "yes" and "maybe" will be considered, as their cumulative probability is greater than 90%. If top-p is 99%, then "yes", "maybe", and "no" are considered.
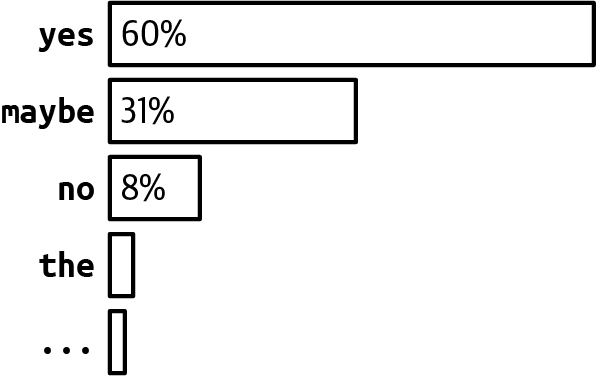
Figure 2-18. Example token probabilities.
Unlike top-k, top-p doesn't necessarily reduce the softmax computation load. Its benefit is that because it focuses only on the set of most relevant values for each context, it allows outputs to be more contextually appropriate. In theory, there don't seem to be a lot of benefits to top-p sampling. However, in practice, top-p sampling has proven to work well, causing its popularity to rise.
A related sampling strategy is min-p, where you set the minimum probability that a token must reach to be considered during sampling.
Stopping Condition
An autoregressive language model generates sequences of tokens by generating one token after another. A long output sequence takes more time, costs more compute (money),5 and can sometimes annoy users. We might want to set a condition for the model to stop the sequence.
Fixed Token Limit
Stop Tokens or Words
Stopping conditions are helpful to keep latency and costs down.
Test Time Compute
The last section discussed how a model might sample the next token. This section discusses how a model might sample the whole output.
One simple way to improve a model's response quality is test time compute: instead of generating only one response per query, you generate multiple responses to increase the chance of good responses.
Best of N
Beam Search
Diverse Samples
Selecting the Best Output
To pick the best output, you can either show users multiple outputs and let them choose the one that works best for them, or you can devise a method to select the best one.
Highest Probability
One selection method is to pick the output with the highest probability. A language model's output is a sequence of tokens, and each token has a probability computed by the model. The probability of an output is the product of the probabilities of all tokens in the output.
Consider the sequence of tokens ["I", "love", "food"]. If the probability for "I" is 0.2, the probability for "love" given "I" is 0.1, and the probability for "food" given "I" and "love" is 0.3, the sequence's probability is: 0.2 x 0.1 x 0.3 = 0.006. Mathematically, this can be denoted as follows:
Remember that it's easier to work with probabilities on a log scale. The logarithm of a product is equal to a sum of logarithms, so the logprob of a sequence of tokens is the sum of the logprob of all tokens in the sequence:
Reward Models and Verifiers
Another selection method is to use a reward model to score each output, as discussed in the previous section. Recall that both Stitch Fix and Grab pick the outputs given high scores by their reward models or verifiers. Nextdoor found that using a reward model was the key factor in improving their application's performance (2023).
OpenAI also trained verifiers to help their models pick the best solutions to math problems (Cobbe et al., 2021). They found that using a verifier significantly boosted the model performance.
DeepMind further proves the value of test time compute, arguing that scaling test time compute, e.g. allocating more compute to generate more outputs during inference, can be more efficient than scaling model parameters (Snell et al., 2024). The same paper asks an interesting question: If an LLM is allowed to use a fixed but nontrivial amount of inference-time compute, how much can it improve its performance on a challenging prompt?
How Much Test Time Compute Helps
In OpenAI's experiment, sampling more outputs led to better performance, but only up to a certain point. In this experiment, that point was 400 outputs. Beyond this point, performance decreases, as shown in Figure 2-19. They hypothesized that as the number of sampled outputs increases, the chance of finding adversarial outputs that can fool the verifier also increases.
However, a Stanford experiment showed a different conclusion. "Monkey Business" (Brown et al., 2024) finds that the number of problems solved often increases log-linearly as the number of samples increases from 1 to 10,000.
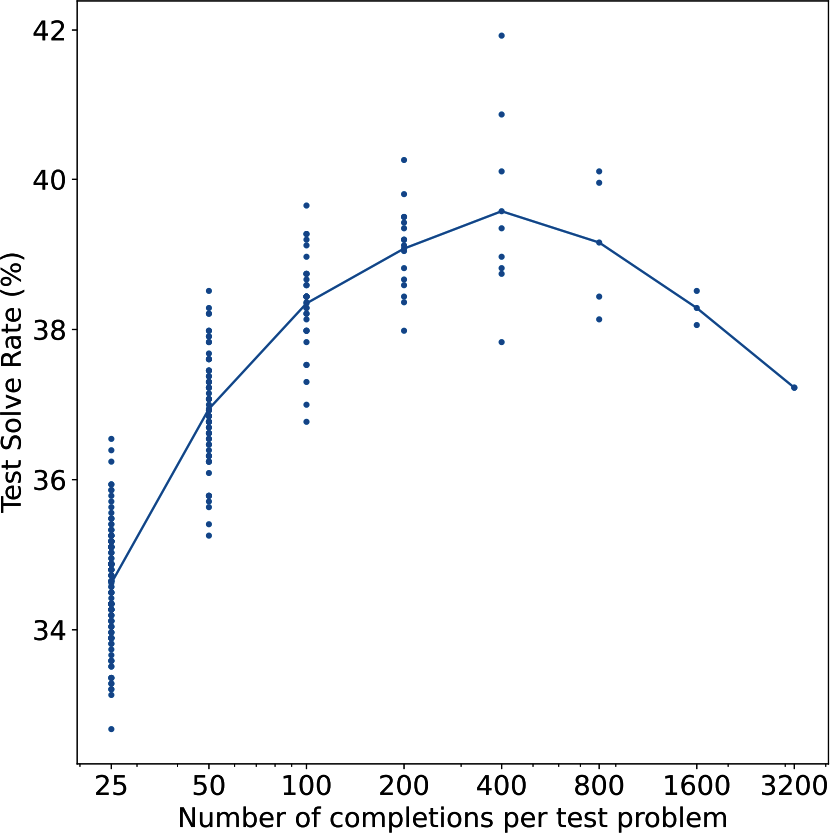
Figure 2-19. OpenAI (2021) found that sampling more outputs led to better performance, but only up to 400 outputs.
Application-Specific Selection
You can also use application-specific heuristics to select the best response.
Shorter Responses
Valid SQL
Lower Latency
Picking out the most common output among a set of outputs can be especially useful for tasks that expect exact answers.8 For example, given a math problem, the model can solve it multiple times and pick the most frequent answer as its final solution. Similarly, for a multiple-choice question, a model can pick the most frequent output option. This is what Google did when evaluating Gemini on the MMLU benchmark. They sampled 32 outputs for each question. This allowed the model to achieve a higher score than what it would've achieved with only one output per question.
A model is considered robust if it doesn't dramatically change its outputs with small variations in the input. The less robust a model is, the more you can benefit from sampling multiple outputs.9 For one project, we used AI to extract certain information from an image of the product. We found that for the same image, our model could read the information only half of the time. For the other half, the model said that the image was too blurry or the text was too small to read. However, by trying three times with each image, the model was able to extract the correct information for most images.
Structured Outputs
Often, in production, you need models to generate outputs following certain formats. Structured outputs are crucial for the following two scenarios:
Tasks Requiring Structure
Downstream Applications
{"title": [TITLE], "body": [EMAIL BODY]}.Semantic parsing allows users to interact with APIs using a natural language, e.g. English. For example, text-to-PostgreSQL allows users to query a Postgres database using English queries such as "What's the average monthly revenue over the last 6 months" instead of writing it in PostgreSQL.
Text-to-Regex Example
This is an example of a prompt for GPT-4o to do text-to-regex. The outputs are actual outputs generated by GPT-4o:
System prompt
Given an item, create a regex that represents all the ways the item can be written. Return only the regex.
Example:
US phone number -> \+?1?\s?(\()?(\d{3})(?(1)\))[-.\s]?(\d{3})[-.\s]? (\d{4})
User prompt
Email address ->
GPT-4o
[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}
User prompt
Dates ->
GPT-4o
(?:\d{1,2}[\/\-\.])(?:\d{1,2}[\/\-\.])?\d{2,4}
Other categories of tasks in this scenario include classification where the outputs have to be valid classes.
Structured Output Tooling
Frameworks that support structured outputs include guidance, outlines, instructor, and llama.cpp. Each model provider might also use their own techniques to improve their models' ability to generate structured outputs.
OpenAI was the first model provider to introduce JSON mode in their text generation API.
Figure 2-20 shows two examples of using guidance to generate outputs constrained to a set of options and a regex.

Figure 2-20. Using guidance to generate constrained outputs.
Five Ways to Guide Structured Outputs
You can guide a model to generate structured outputs at different layers of the AI stack: prompting, post-processing, test time compute, constrained sampling, and finetuning.
Test time compute has just been discussed in the previous section -- keep on generating outputs until one fits the expected format. This section focuses on the other four approaches.
Prompting
Prompting is the first line of action for structured outputs. You can instruct a model to generate outputs in any format. However, whether a model can follow this instruction depends on the model's instruction-following capability, discussed in Chapter 4, and the clarity of the instruction, discussed in Chapter 5. While models are getting increasingly good at following instructions, there's no guarantee that they'll always follow your instructions.10 A few percentage points of invalid model outputs can still be unacceptable for many applications.
This means that for each output, there will be at least two model queries: one to generate the output and one to validate it. While the added validation layer can significantly improve the validity of the outputs, the extra cost and latency incurred by the extra validation queries can make this approach too expensive for some.
Post-processing
Post-processing is simple and cheap but can work surprisingly well. During my time teaching, I noticed that students tended to make very similar mistakes. When I started working with foundation models, I noticed the same thing. A model tends to repeat similar mistakes across queries. This means if you find the common mistakes a model makes, you can potentially write a script to correct them.
Post-processing works only if the mistakes are easy to fix. This usually happens if a model's outputs are already mostly correctly formatted, with occasional small errors.
Constrained Sampling
Constrained sampling is a technique for guiding the generation of text toward certain constraints. It is typically followed by structured output tools.
At a high level, to generate a token, the model samples among values that meet the constraints. Recall that to generate a token, your model first outputs a logit vector, each logit corresponding to one possible token. Constrained sampling filters this logit vector to keep only the tokens that meet the constraints. It then samples from these valid tokens.
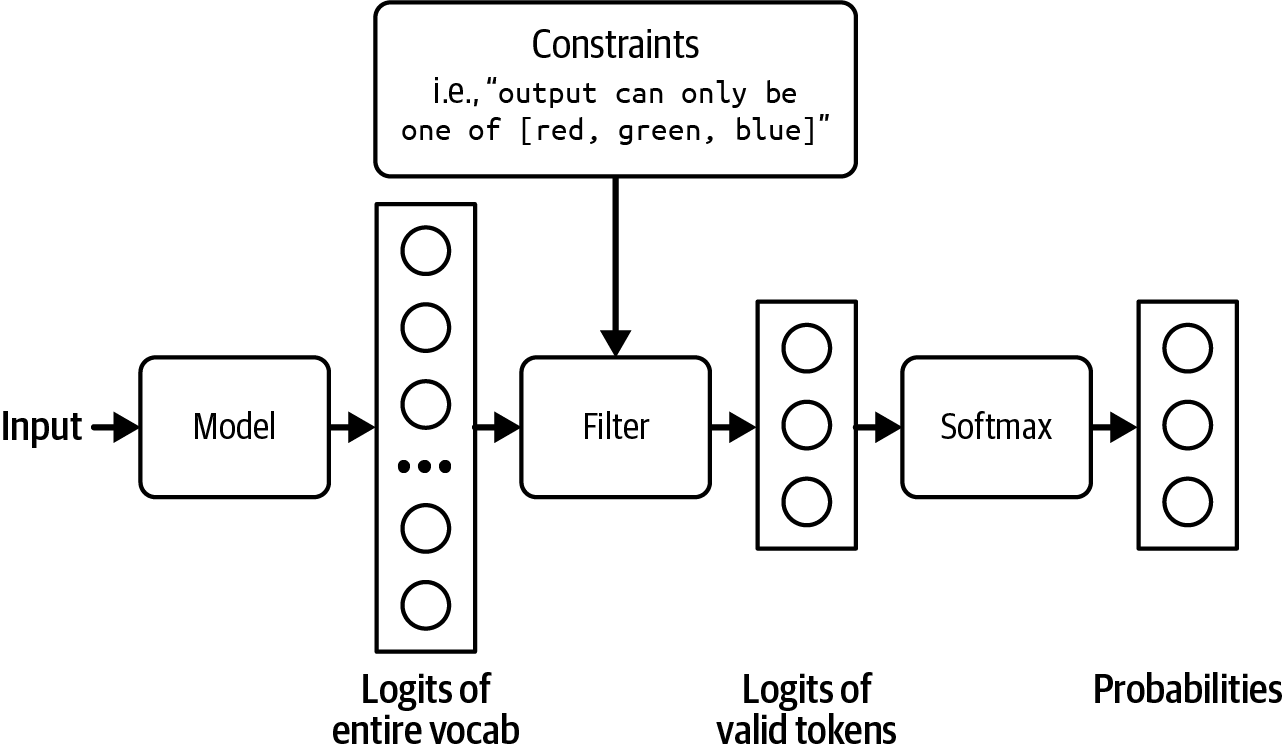
Figure 2-21. Filter out logits that don't meet the constraints in order to sample only among valid outputs.
In the example in Figure 2-21, the constraint is straightforward to filter for. However, most cases aren't that straightforward. You need to have a grammar that specifies what is and isn't allowed at each step. For example, JSON grammar dictates that after {, you can't have another { unless it's part of a string, as in {"key": "{{string}}"}.
Some are against constrained sampling because they believe the resources needed for constrained sampling are better invested in training models to become better at following instructions.
Finetuning
Finetuning a model on examples following your desirable format is the most effective and general approach to get models to generate outputs in this format.11 It can work with any expected format. While simple finetuning doesn't guarantee that the model will always output the expected format, it is much more reliable than prompting.
For certain tasks, you can guarantee the output format by modifying the model's architecture before finetuning. For example, for classification, you can append a classifier head to the foundation model's architecture to make sure that the model outputs only one of the pre-specified classes. The architecture looks like Figure 2-22.12 This approach is also called feature-based transfer and is discussed more with other transfer learning techniques in Chapter 7.
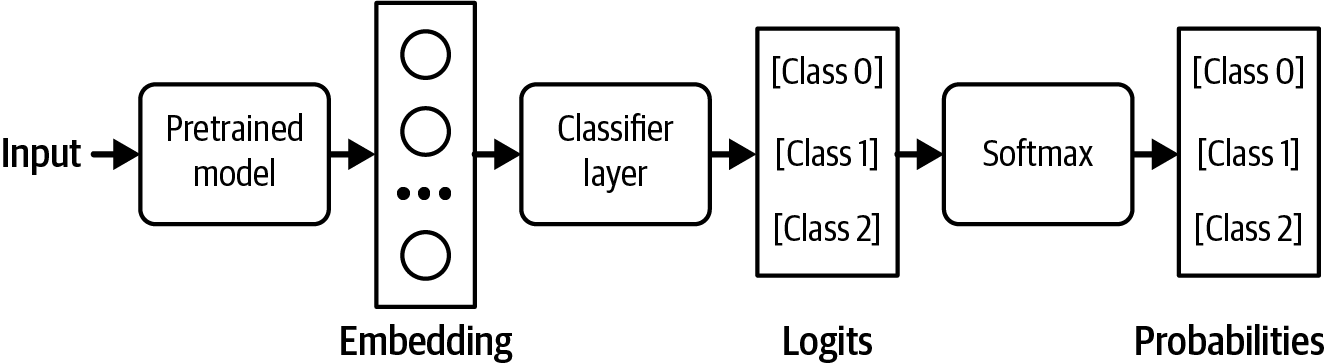
Figure 2-22. Adding a classifier head to your base model to turn it into a classifier. In this example, the classifier works with three classes.
During finetuning, you can retrain the whole model end-to-end or part of the model, such as this classifier head. End-to-end training requires more resources, but promises better performance.
The Probabilistic Nature of AI
The way AI models sample their responses makes them probabilistic. Imagine that you want to know what's the best cuisine in the world. If you ask your friend this question twice, a minute apart, your friend's answers both times should be the same. If you ask an AI model the same question twice, its answer can change.
This probabilistic nature can cause inconsistency and hallucinations.
Inconsistency
Hallucination
Imagine if someone on the internet wrote an essay about how all US presidents are aliens, and this essay was included in the training data. The model later will probabilistically output that the current US president is an alien. From the perspective of someone who doesn't believe that US presidents are aliens, the model is making this up.
This characteristic makes building AI applications both exciting and challenging. Many of the AI engineering efforts, as we'll see in this book, aim to harness and mitigate this probabilistic nature.
Great for Creativity
Painful for Reliability
Inconsistency
Model inconsistency manifests in two scenarios:
Same Input, Different Outputs
Slightly Different Input, Drastic Output
Figure 2-23 shows an example of me trying to use ChatGPT to score essays. The same prompt gave me two different scores when I ran it twice: 3/5 and 5/5.

Figure 2-23. The same input can produce different outputs in the same model.
Inconsistency can create a jarring user experience. In human-to-human communication, we expect a certain level of consistency. Imagine a person giving you a different name every time you see them. Similarly, users expect a certain level of consistency when communicating with AI.
Mitigating Inconsistency
For the same input, different outputs scenario, there are multiple approaches to mitigate inconsistency.
Cache Answers
Fix Sampling Variables
Fix the Seed
If you host your models, you have some control over the hardware you use. However, if you use a model API provider like OpenAI or Google, it's up to these providers to give you any control.
Fixing the output generation settings is a good practice, but it doesn't inspire trust in the system. Imagine a teacher who gives you consistent scores only if that teacher sits in one particular room. If that teacher sits in a different room, that teacher's scores for you will be wild.
The second scenario -- slightly different input, drastically different outputs -- is more challenging. Fixing the model's output generation variables is still a good practice, but it won't force the model to generate the same outputs for different inputs. It is, however, possible to get models to generate responses closer to what you want with carefully crafted prompts, discussed in Chapter 5, and a memory system, discussed in Chapter 6.
Hallucination
Hallucinations are fatal for tasks that depend on factuality. If you're asking AI to help you explain the pros and cons of a vaccine, you don't want AI to be pseudo-scientific. In June 2023, a law firm was fined for submitting fictitious legal research to court. They had used ChatGPT to prepare their case, unaware of ChatGPT's tendency to hallucinate.
While hallucination became a prominent issue with the rise of LLMs, hallucination was a common phenomenon for generative models even before the term foundation model and the transformer architecture were introduced. Hallucination in the context of text generation was mentioned as early as 2016 (Goyal et al., 2016). Detecting and measuring hallucinations has been a staple in natural language generation (NLG) since then (see Lee et al., 2018; Nie et al., 2019; and Zhou et al., 2020).
If inconsistency arises from randomness in the sampling process, the cause of hallucination is more nuanced. The sampling process alone doesn't sufficiently explain it. A model samples outputs from all probable options. But how does something never seen before become a probable option?
It's hard to devise a way to eliminate hallucinations without understanding why hallucinations occur in the first place. There are currently two hypotheses about why language models hallucinate.
Hypothesis 1: Self-Delusion
The first hypothesis, originally expressed by Ortega et al. at DeepMind in 2021, is that a language model hallucinates because it can't differentiate between the data it's given and the data it generates.
Imagine that you give the model the prompt: "Who's Chip Huyen?" and the first sentence the model generates is: "Chip Huyen is an architect." The next token the model generates will be conditioned on the sequence: "Who's Chip Huyen? Chip Huyen is an architect." The model treats "Chip Huyen is an architect.", something it produced, the same way it treats a given fact.
Figure 2-24 shows an example of self-delusion by the model LLaVA-v1.5-7B. I asked the model to identify ingredients listed on the product's label in the image, which is a bottle of shampoo. In its response, the model convinces itself that the product in the image is a bottle of milk, then continues to include milk in the list of ingredients extracted from the product's label.

Figure 2-24. An example of self-delusion by LLaVA-v1.5-7B.
Zhang et al. (2023) call this phenomenon snowballing hallucinations. After making an incorrect assumption, a model can continue hallucinating to justify the initial wrong assumption. Interestingly, the authors show that initial wrong assumptions can cause the model to make mistakes on questions it would otherwise be able to answer correctly, as shown in Figure 2-25.
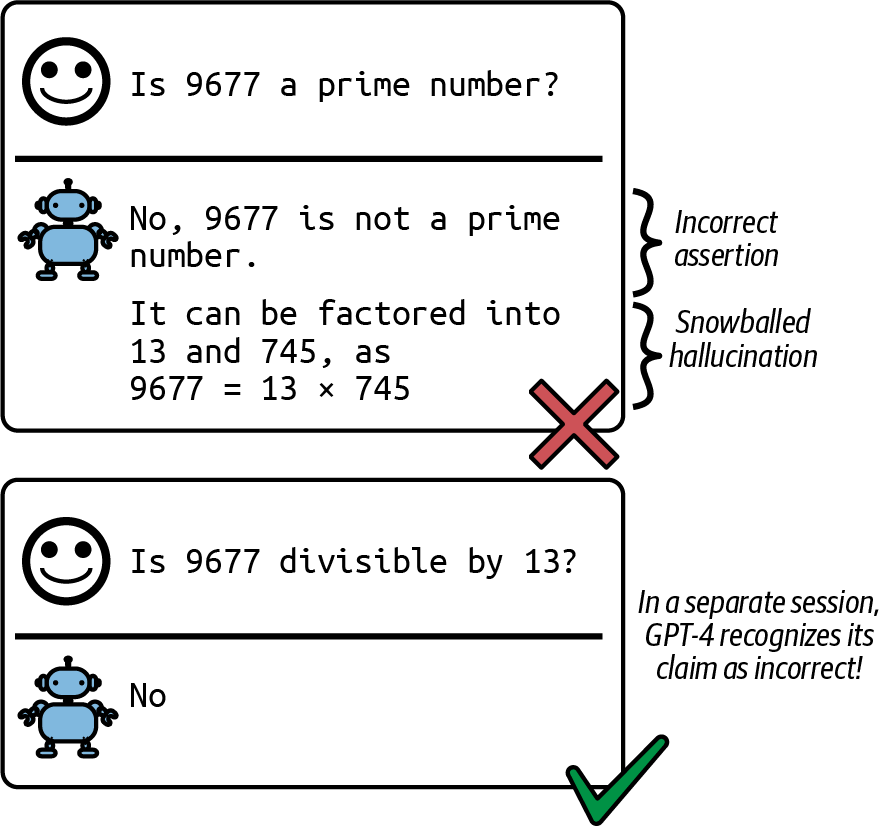
Figure 2-25. An initial incorrect assumption can cause the model to claim that 9677 is divisible by 13, even if it knows this isn't true.
The DeepMind paper showed that hallucinations can be mitigated by two techniques.
Separate Observations and Actions
Add Factual Signals
Hypothesis 2: Mismatched Internal Knowledge
The second hypothesis is that hallucination is caused by the mismatch between the model's internal knowledge and the labeler's internal knowledge. This view was first argued by Leo Gao, an OpenAI researcher.
During SFT, models are trained to mimic responses written by labelers. If these responses use the knowledge that the labelers have but the model doesn't have, we're effectively teaching the model to hallucinate. In theory, if labelers can include the knowledge they use with each response they write so that the model knows that the responses aren't made up, we can perhaps teach the model to use only what it knows. However, this is impossible in practice.
In April 2023, John Schulman, an OpenAI co-founder, expressed the same view in his UC Berkeley talk. Schulman also believes that LLMs know if they know something, which, in itself, is a big claim. If this belief is true, hallucinations can be fixed by forcing a model to give answers based on only the information it knows.
Verification
Reinforcement Learning
Remember that the reward model is trained using only comparisons -- response A is better than response B -- without an explanation of why A is better.
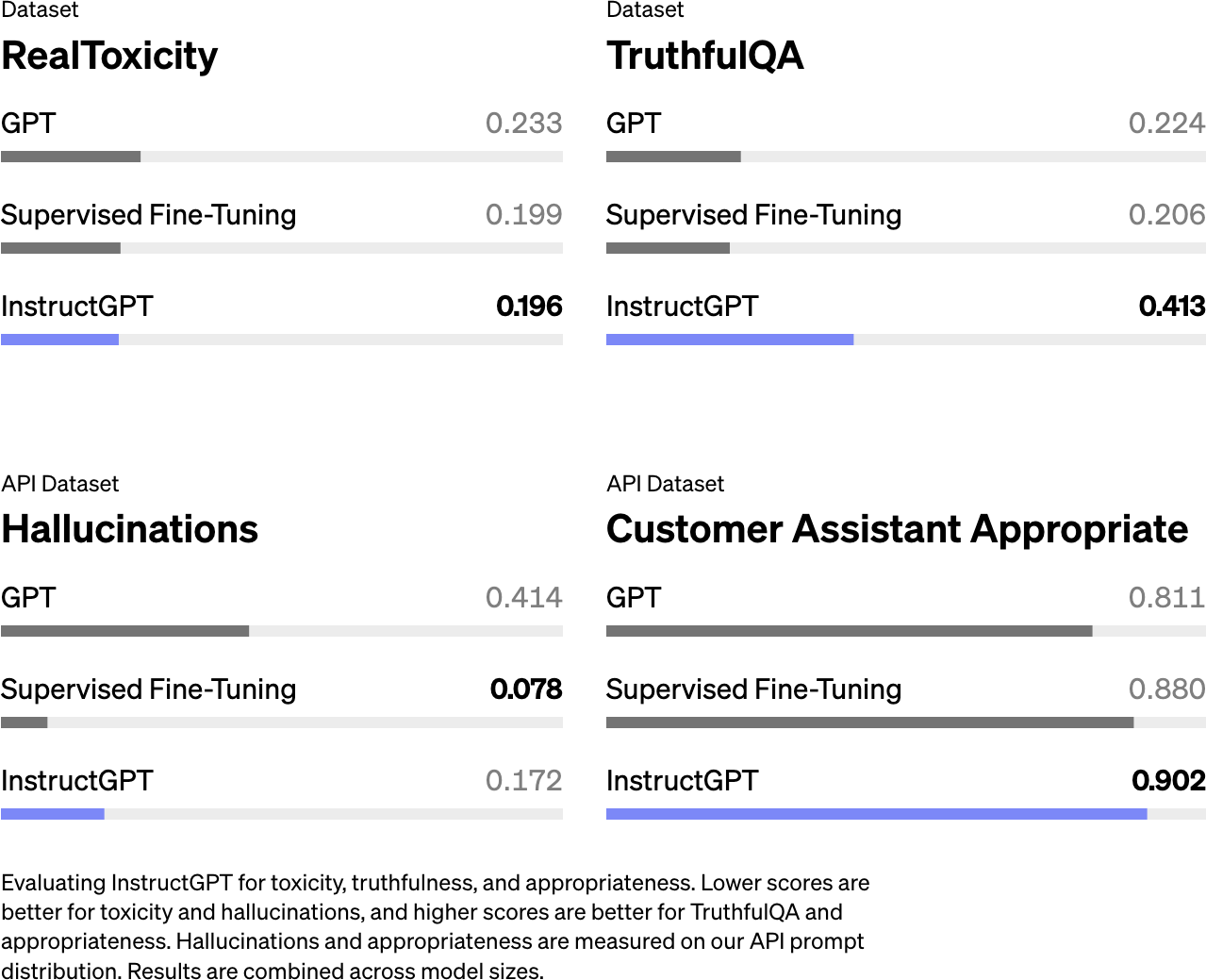
Figure 2-26. Hallucination is worse for the model that uses both RLHF and SFT (InstructGPT) compared to the same model that uses only SFT (Ouyang et al., 2022).
Based on the assumption that a foundation model knows what it knows, some people try to reduce hallucination with prompts, such as adding "Answer as truthfully as possible, and if you're unsure of the answer, say, 'Sorry, I don't know.'" Asking models for concise responses also seems to help with hallucinations -- the fewer tokens a model has to generate, the less chance it has to make things up. Prompting and context construction techniques in Chapters 5 and 6 can also help mitigate hallucinations.
If we can't stop hallucinations altogether, can we at least detect when a model hallucinates so that we won't serve those hallucinated responses to users? Detecting hallucinations isn't that straightforward either -- think about how hard it is for us to detect when another human is lying or making things up. But people have tried. We discuss how to detect and measure hallucinations in Chapter 4.
Footnotes
- A visual image I have in mind when thinking about temperature, which isn't entirely scientific, is that a higher temperature causes the probability distribution to be more chaotic, which enables lower-probability tokens to surface. ↩
- Performing an arg max function. ↩
- The underflow problem occurs when a number is too small to be represented in a given format, leading to it being rounded down to zero. ↩
- To be more specific, as of this writing, OpenAI API only shows you the logprobs of up to the 20 most likely tokens. It used to let you get the logprobs of arbitrary user-provided text but discontinued this in September 2023. Anthropic doesn't expose its models' logprobs. ↩
- Paid model APIs often charge per number of output tokens. ↩
- There are things you can do to reduce the cost of generating multiple outputs for the same input. For example, the input might only be processed once and reused for all outputs. ↩
- As of this writing, in the OpenAI API, you can set the parameter best_of to a specific value, say 10, to ask OpenAI models to return the output with the highest average logprob out of 10 different outputs. ↩
- Wang et al. (2023) called this approach self-consistency. ↩
- The optimal thing to do with a brittle model, however, is to swap it out for another. ↩
- As of this writing, depending on the application and the model, I've seen the percentage of correctly generated JSON objects anywhere between 0% and up to the high 90%. ↩
- Training a model from scratch on data following the desirable format works too, but this book isn't about developing models from scratch. ↩
- Some finetuning services do this for you automatically. OpenAI's finetuning services used to let you add a classifier head when training, but as I write, this feature has been disabled. ↩
- As the meme says, the chances are low, but never zero. ↩
- In December 2023, I went over three months' worth of customer support requests for an AI company I advised and found that one-fifth of the questions were about handling the inconsistency of AI models. In a panel I participated in with Drew Houston (CEO of Dropbox) and Harrison Chase (CEO of LangChain) in July 2023, we all agreed that hallucination is the biggest blocker for many AI enterprise use cases. ↩